Java 多态
父类对象引用子类实例。子类继承父类后,同一个方法有不同的表现。
- 方法重载实现静态多态性(编译时多态)
- 方法重写实现的动态多态性(运行时多态)
Java 虚拟机
Java程序执行过程
- Java Source (.java File)
- Java Compiler(javac)
- Java Byte Code(.class File)
- Class Loader
- Execution Engine
- Runtime Data Areas
- Java Virtual Machine
类加载器 ( **Class Loader ** )
- Bootstrap Class Loader
- Extension Class Loader
- System Class Loader
- User-Defined Class Loader
运行数据区域 ( Runtime Data Areas )
PC Register
每个线程有一个PC计数器。当线程启动时,PC计数器被创建,这个计数器存放当前正在被执行的字节码指令( JVM 指令 )的地址。JVM Stack
Java栈中存放着一系列的栈桢( Stack Frame ),JVM 只能进行压入( Push ) 和弹出 ( Pop ) 栈帧这两种操作。每当调用 一个方法时,JVM就往栈里压入一个栈帧,方法结束返回时弹出栈帧。如果方法执行时异常,可以调用printStackTrace 等方法来查看栈的情况。- Stack Frame
- Local Variable Array 局部变量队列
- Operand Stack 操作数栈
- Reference to Constant Pool常量池引用
- Stack Frame
Native Method Stack
当程序通过 JNI(Java Native Interface)调用本地方法(如 C 或者 C++ 代码)时,就根据本地方法的语言类型建立相应的栈。Heap
堆中存放的是程序创建的对象或者实例。这个区域对 JVM 的性能影响很大。垃圾回收机制处理的正是这一块内存区域。 所以,类加载器加载其实就是根据编译后的 Class 文件,将 java 字节码载入 JVM 内存,并完成对运行数据处的初始化工作,供执行引擎执行。Method Area
方法区域是一个 JVM 实例中的所有线程共享的,当启动一个 JVM 实例时,方法区域被创建。它用于存运行时常量池、有关域和方法的信息、静态变量、类和方法的字节码。不同的 JVM 实现方式在实现方法区域的时候会有所区别。Oracle 的 HotSpot 称之为永久区域(Permanent Area)或者永久代(Permanent Generation)。Runtime Constant Pool
这个区域存放类和接口的常量,除此之外,它还存放方法和域的所有引用。当一个方法或者域被引用的时候,JVM 就通过运行常量池中的这些引用来查找方法和域在内存中的的实际地址。
前三个属于每个线程独自拥有。后三者是整个JVM实例中所有线程共有的。
执行引擎 (Execution Engine )
类加载器将字节码载入内存之后,执行引擎以Java字节码指令为单元,读取Java字节码。通过解释器将字节码转化成平台相关的机器码,这个过程也可以由即时编译器 ( JIT Compiler ) 来完成。
Java内存管理
Java的内存管理就是对象的分配和释放问题。
分配
内存分配由程序完成,使用 new 关键词为对象申请内存空间(基本类型除外),所有的对象都在堆( Heap ) 中分配空间。
释放
对象的释放由垃圾回收机制( GC )决定和执行。
Java的内存区域分栈内存和堆内存
栈内存
在函数中定义的基本类型变量和对象的引用变量都在函数的栈内存中分配。在函数(代码块)中定义一个变量时, java 就在栈中为这个变量分配内存空间,当超过变量的作用域后,java 会自动释放掉为该变量所分配的内存空间。
堆内存
用来存放由 new 创建的对象和数组以及对象的实例变量。在堆中分配的内存由 java 虚拟机的自动垃圾回收器来管理。
- 堆的优点是可以动态分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的。缺点是在运行时动态分配内存,存取速度较慢
- 栈的优点是存取速度比堆要快,仅次于直接位于CPU中的寄存器。另外栈数据可以共享。缺点是存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
Java中数据在内存中的存储位置
基本数据类型(8种,即int, short, long, byte, float, double, boolean, char)。保存在栈中,并且共享。所以
1
2
3String s1 = "a";
String s2 = "a";
System.out.println(s1==s2);//true对象
1
2
3
4
5
6
7
8
9
10
11
12public class Person {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
Person p = new Person("joally", 24);
//1.Person p声明一个对象Person,其引用命名为p,此时在栈内存中为引用变量p分配内存空间,此时p是空对象,等同于Person p = null;
//2.p = new Person("joally", 24)在堆内存中为类的成员变量name和age分配内存,并将其初始化为各数据类型的默认值;接着进行显式初始化(类定义时的初始化值);最后调用构造方法,为成员变量赋值。返回堆内存中对象的引用(相当于首地地址)给引用变量p,以后就可以通过栈内存中的p来引用堆内存中的Person对象了。数组
当定义一个数组时,在栈内存中创建一个数组引用,通过该引用(即数组名)来引用数组。
1
2int x[]; //在栈内存中创建数组引用x;
x = new int[3];//在堆内存中分配3个保存int型数据的空间,并初始化为0,堆内存的首地址赋值给x,即通过栈内存中x来引用堆内存中的int数组。静态变量
用static修饰的变量和方法,实际上是指定了这些变量和方法在内存中的“固定位置” - static stoage,可以理解为所有实例对象共有的内存空间。静态表示的的是内存的共享,就是它的每一个实例都指向同一个内存地址,它的引用(含间接引用)都指向同一个位置。
Java 程序的多个部分(方法,变量,对象)驻留在内存中以下两个位置:堆和栈。实例变量和对象驻留在堆上,局部变量驻留在栈上。
1 | public class Dog { |
Java泛型
泛型的主要目标是提高 Java 程序的类型安全。消除强制类型转换,提高代码可读性,减少出错机会。
Java序列化
定义
序列化,就是为了保存对象的状态,与之对应的是反序列化,就是把保存的对象状态再读出来。
序列化/反序列化,是Java提供一种专门用于保存/恢复对象状态的机制。
一般以下几种情况下,我们可能会用到序列化:
- 想把内存中的对象状态保存到一个文件中或数据库中
- 想用套接字在网络上传送对象
- 想通过RMI ( Remote Method Invocation 远程连接调用 ) 传输对象时
java.io.Serializable
类通过实现Serializable接口,可实现自动序列化
- transient瞬态,用于不序列化的属性
- 静态变量,属于类的状态,不序列化
- 如果想自定义序列化的内容,类中需要实现
writeObject(java.io.ObjectOutputStream o)/readObject(java.io.ObjectInputStream o)方法,分别用于序列化和反序列化。自定义方法第一行可调用out.defaultWriteObject()/out.defaultReadObject()来调用jdk的默认序列化,然后再实现自己的序列化
java.io.Externalizable
如果一个类要完全负责自己的序列化,则实现 Externalizable 接口,而不是 Serializable 接口。
Externalizable接口定义包括两个方法
writeExternal()与readExternal()。需要注意的是:声明类实现Externalizable接口会有重大的安全风险。writeExternal()与readExternal()方法声明为public,恶意类可以用这些方法读取和写入对象数据。如果对象包含敏感信息,则要格外小心。
writeExternal(ObjectOutput out)readExernal(ObjectInput in)readResolve/writeReplace可以用在单例模式时的序列化和反序列化,用于指定替代的对象
Java基本数据结构
- boolean、char[2byte,16bit]、short[2byte,16bit]、int[4byte,32bit]、float[4byte,64bit]、long[8byte,64bit]、double[8byte,64bit]
- 基本数据包装类,继承于
java.lang.Number类,包括:java.lang.Byte、java.lang.Short、java.lang.Integer、java.lang.Float、java.lang.Long、java.lang.Double,以及java.lang.Boolean、java.lang.Character - Java字符,原始类型
char,包装类java.lang.Character,jdk6基于Unicode Standard version4.0,jdk7基于Unicode Standard version6.0,jdk8基于Unicode verison6.2.0。 - Unicode编码,使用“U+”然后紧接着一组十六进制的数字表示一个字符。从U+0000到U+FFFF的字符集被称作Basic Multilingual Plane(BMP),又称作
零号平面,其中的所有字符,要用四个数字(即2个char,16bit,例如U+4AE0,共支持2^16-1=65535个字符);在零号平面以外的字符则需要使用五个或六个数字,范围为U+0000到U+10FFFF,即通常所说的Unicode标准量。 - java.lang.Math、java.util.Date、java.text.SimpleDateFormat、java.text.NumberFormat、java.text.MessageFormat、java.util.Calendar、java.util.GregorianCalendar
Java正则表达式
java.util.regex包主要包含三个类
Pattern类
一个Pattern对象是正则表达式编译表示。 Pattern 类没有提供公共的构造函数。要创建一个 Pattern 对象,你必须首先调用他的公用静态编译方法来获得 Pattern 对象。这些方法的第一个参数是正则表达式。
Matcher类
一个Matcher对象是用来解释模式和执行与输入字符串相匹配的操作。和Pattern类一样Matcher类也是没有构造方法的,你需要通过调用 Pattern对象的matcher方法来获得Matcher对象。
PatternSyntaxExceptiopn类
一个PatternSyntaxException对象是一个不被检查的异常,来指示正则表达式中的语法错误。
1 | String text = "gogo"; |
正则表达式语法
字符
对应其8进制,16进制,或者unicode编码
John=101=\x41=\u0041\\反斜线\0n带有八进制值0的字符n(0 <= n <= 7)\0nn带有八进制值0的字符nn(0 <= n <= 7)\0mnn带有八进制值0的字符mnn(0 <= m <= 3、0 <= n <= 7)\xhh带有十六进制值0x的字符hh\uhhhh带有十六进制值0x的字符hhhh\t制表符(\u009)\n新行(换行)符(\u000A)\r回车符(\u000D)\f换页符(\u000C)\a报警(bell)符(\u0007)\e转义符(\u001B)\cx对应于x的控制符
字符类
使用方括号[]表示字符组。可以匹配方括号中一个或多个字符。方括号本身并不是要匹配的一部分。
[abc]、[a-zA-Z]、[a-z&&[def]]表示匹配d、e或f、[a-z&&[^bc]]=[ad-z]
预定义字符类
.任何字符(与行结束符可能匹配也可能不匹配)\d数字:[0-9]\D非数字:[^0-9]\s空白字符:[ \t\n\x[0B\f\r\]]\w单词字符:[a-zA-Z_0-9]\W非单词字符:[^w]
边界匹配
^行的开头$行的结尾\b单词边界\B非单词边界\A输入的开头\G上一个匹配的结尾\Z输入的结尾,仅用于最后的结束符(如果有的话)\z输入的结尾
数量词
数量词匹配分为贪婪模式,饥饿模式,独占模式。饥饿模式匹配尽可能少的文本。贪婪模式匹配尽可能多的文本。独占模式匹配尽可能多的文本,基本导致剩余表达式匹配失败。
X?、X??、X?+一次或一次也没有X*、X*?、X*+零次或多次X+、X+?、X++一次或多次X{n}、X{n}?、X{n}+正好n次X{n,}、X{n,}?、X{n,}+至少n次X{n,m}、X{n,m}?、X{n,m}+至少n次,不超过m次
逻辑操作符
- XY表示and
- X|Y表示X或Y
- (X)表示捕获组
特殊构造(非捕获)
(?:X)X,作为非捕获组,匹配X,不捕获匹配的文本,也不给此分组分配组号(?=X)X,通过零宽度的正lookahead,匹配X前面的位置(?!X)X,通过零宽度的负lookahead,匹配后面跟的不是X的位置(?<=X)X,通过零宽度的正lookbehind,匹配X后面的位置(?<!X)X,通过零宽度的负lookbehind,匹配前面不是X的位置(?>X)X,作为独立的非捕获组,贪婪子表达式
后向引用
\n,n为数字,表示前面第n个捕获组(?<name>X)X,匹配X,并捕获X到名称为name的组里,等同于(?'name'X)\k<name>匹配前面命名的捕获组,对应于(?<name>)或(?'name')
平衡组/递归匹配
Java IO
java.io包主要涉及文件访问、网络数据流、内存缓冲访问、线程内部通信(管道)、缓冲、过滤、解析、读写文件(Readers/Writers)、读写基本类型数据(long,int etc)、读写对象等输入输出。
字节流
InputStream字节输入流
- ByteArrayInputStream
- FileInputStream
- FilterInputStream
- BufferedInputStream
- DataInputStream
LineNumberInputStream- PushbackInputStream
- ObjectInputStream
- PipedInputStream
- SequenceInputStream
- StringBufferStream
OutputStream字节输出流
- ByteArrayOutputStream
- FileOutputStream
- FilterOutputStream
- BufferedOutputStream
- DataOutputStream
- PrintStream
- ObjectOutputStream
- PipedOutputStream
字符流
Reader字符输入流
- BufferedReader
- LineNumberReader
- CharArrayReader
- FilterReader
- PushbackReader
- InputStreamReader
- FileReader
- PipedReader
- StringReader
Writer字符输出流
- BufferedWriter
- CharArrayWriter
- FilterWriter
- OutputStreamWriter
- FileWriter
- PipedWriter
- PrintWriter
- StringWriter
Java异常处理
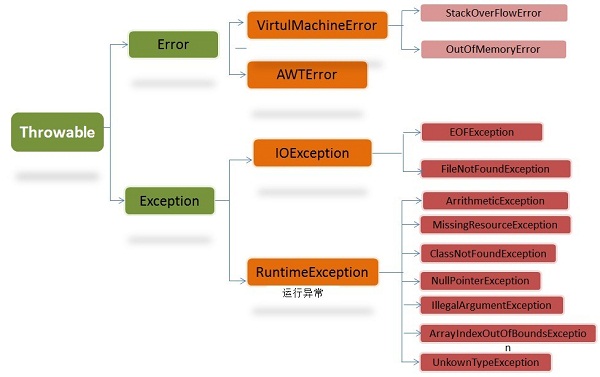
Throwable
- Error
错误,是程序无法处理的错误,表示运行应用程序中较严重问题。属于不可检测的异常(Unchecked Excepiton) - Exception
异常,是程序本身可以处理的异常。分为可检测异常(Checked Exception)、运行时异常(Runtime Exception)。- IOException
可检测异常通常是用户错误或是程序员可预计的,需要在编译时处理,一般用try-catch语句捕获或者用throws子句声明抛出。 - RuntimeException
运行时异常程序可以选择捕获处理,也可以不处理,这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。属于不可检测的异常(Unchecked Excepiton)。
- IOException
- Error
Java集合
总体框架
Java集合是Java提供的工具包,包含了常用的数据结构:集合、链表、队列、栈、数组、映射等。Java集合工具包位置是
java.util.*Java集合主要可以划分为4个部分:List列表、Set集合、Map映射、工具类(Iterator迭代器、Enumeration枚举类、Arrays和Collections)。
主要类:
ArrayList、LinkedList、HashMap、LinkedHashMap、TreeMap、HashSet、LinkedHashSet主体:
Collection接口、Map接口
主要接口
CollectionListSetSortedSetNavigableSet
QueueDeque
MapSortedMapNavigableMap
IteratorListIterator
主要类
AbstractCollectionAbstractListAbstractSequentialListLinkedList
链表
ArrayList
动态数组
AbstractQueuePriorityQueue
AbstractSetEnumSetHashSet
基于HashMap的Set接口的数组和链表实现LinkedHashSet
TreeSet
ArrayDeque
AbstractMapEnumMapHashMap
Map接口的数组与链表实现LinkedHashMap
TreeMapWeakHashMapIdentityHashMap
List
ArrayList
List接口的大小可变数组的实现。实现了所有可选列表操作,并允许包括Null在内的所有元素。
1 | //JDK6 |
ArrayList包含了两个重要的对象:elementData 和 size。
elementData是”Object[]类型的数组”,它保存了添加到ArrayList中的元素。实际上,elementData是个动态数组,我们能通过构造函数 ArrayList(int initialCapacity)来执行它的初始容量为initialCapacity;如果通过不含参数的构造函数ArrayList()来创建ArrayList,则elementData的容量默认是10。elementData数组的大小会根据ArrayList容量的增长而动态的增长,具体的增长方式,请参考源码分析中的ensureCapacity()函数。size则是动态数组的实际大小。
fast-fail是一种错误检测机制。当在多线程环境下同时对ArrayList进行读写操作时,会抛出ConcurrentModificationException异常。可使用CopyOnWriteArray,因为CopyOnWriteArray的所有写操作都会copy一份新的数组,而通过Iterator遍历时不支持写操作,因为不会抛出ConcurrentModificationException异常。
LinkedList
List接口的链接列表实现。实现所有可选列表操作,并且允许包括Null在内的所有元素。
是一个继承于AbstractSequentialList的双向链表。可以被当作堆栈、队列 或双端队列进行操作。
1 | //JDK6 |
AbstractSequentialList实现了
get(int index)、set(int index, E element)、add(int index, E element)、remove(int index)函数,这些接口都是随机访问List的。LinkedList的本质是双向链表。LinkedList继承于AbstractSequentialList,并且实现了Dequeue接口。
LinkedList包含两个重要的成员:header 和 size。
- header是双向链表的表头,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
- size是双向链表中节点的个数。
List总结
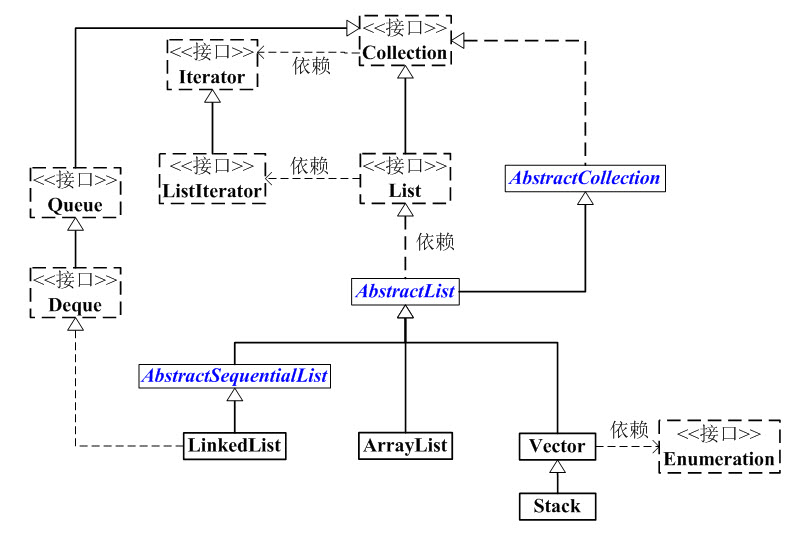
- List 是一个接口,它继承于Collection的接口。它代表着有序的队列。
- AbstractList 是一个抽象类,它继承于AbstractCollection。AbstractList实现List接口中除size()、get(int location)之外的函数。
- AbstractSequentialList 是一个抽象类,它继承于AbstractList。AbstractSequentialList 实现了”链表中,根据index索引值操作链表的全部函数”。
- ArrayList, LinkedList, Vector, Stack是List的4个实现类。
- ArrayList 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。
- LinkedList 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
- Vector 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
- Stack 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。
- 如果涉及到“栈”、“队列”、“链表”等操作,应该考虑用List,具体的选择哪个List,根据下面的标准来取舍。
- 对于需要快速插入,删除元素,应该使用LinkedList。
- 对于需要快速随机访问元素,应该使用ArrayList。
对于“单线程环境” 或者 “多线程环境,但List仅仅只会被单个线程操作”,此时应该使用非同步的类(如ArrayList)。 Vector和Stack使用synchronized关键字来实现线程安全,效果效低,不建议使用。多线程环境需要线程安全的List建议使用CopyOnWriteList。
Map
HashMap
- HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序永久不变。
- HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
- HashMap在底层将key-value当成一个整体进行处理,这个整体就是一个Entry对象。HashMap底层采用一个Entry[]数组来保存所有的key-value对,存储时,会根据hash算法来决定其在数组中的存储 位置,再根据equals方法决定期在数组位置上的链表中的存储位置,取出时,根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
- HashMap的元素大小超过capacity*loadFactor时,就会扩容为原先容量的2倍。capacity为原先容量,loadFactor为负载因子,默认为0.75,负载因子越大,对空间利用越充分,但相应查找效率变低,反之,数据过于稀疏,空间造成浪费。
- Fail-Fast机制,快速失败,HashMap不是线程安全的,当其他线程对其进行修改,当前线程会直接抛出ConcurrentModificationException。
- HashMap是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
- table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
- size是HashMap的大小,它是HashMap保存的键值对的数量。
- threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=”容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
- loadFactor就是加载因子。
- modCount是用来实现fail-fast机制的。
1 | public class HashMap<K,V> |
TreeMap
- TreeMap是一个有序的key-value集合,它是通过
红黑树实现的。 - TreeMap 实现了NavigableMap接口,意味着它**支持一系列的导航方法。**比如返回有序的key集合。
- TreeMap基于**红黑树(Red-Black tree)实现**。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
- TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
- 另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
1 | public class TreeMap<K,V> |
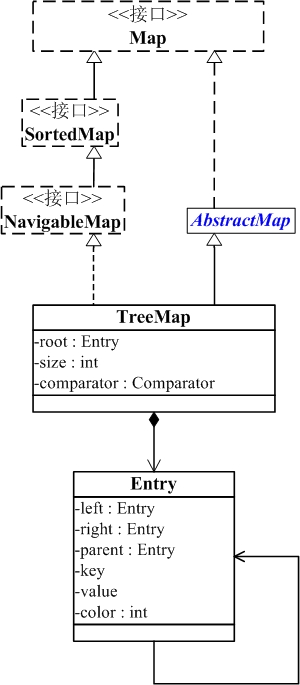
- TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
- TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
- root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
- 红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
- size是红黑数中节点的个数。
LinkedHashMap
- HashMap是无序的,HashMap在put时根据key的hascode进行hash,然后放入对应的地方。
- LinkedHashMap是Map接口的哈希表和链表实现,具有可预知的迭代顺序。允许Null值和Null键。
- LinkedHashMap是HashMap的子类,它保留插入的顺序。底层仍使用哈希表与链表保存所有元素,唯一不同是链表为双向链表,增加前一个元素的地址。
- LinkedHashMap可以通过插入顺序或者访问顺序来迭代其元素。
1 | public class LinkedHashMap<K,V> |
LinkedHashMap 与 LRUcache
由于LinkedHashMap支持设置accessOrder为true后,通过访问顺序来排序元素,因此可以实现LRUcache( Last Recent Use cache最后访问缓存)。
WeakHashMap
- WeakHashMap和HashMap都是通过”拉链法”实现的散列表。它们的源码绝大部分内容都一样,这里就只是对它们不同的部分就是说明。
- WeakReference是“弱键”实现的哈希表。它这个“弱键”的目的就是:实现对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
- “弱键”是一个弱引用(WeakReference),在Java中,
WeakReference和ReferenceQueue是联合使用的。 - WeakHashMap中亦是如此:如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 接着,WeakHashMap会根据“引用队列”,来删除WeakHashMap中已被GC回收的‘弱键’对应的键值对”。
- 另外,理解上面思想的重点是通过
expungeStaleEntries()函数去理解。
1 | public class WeakHashMap<K,V> |
Map总结
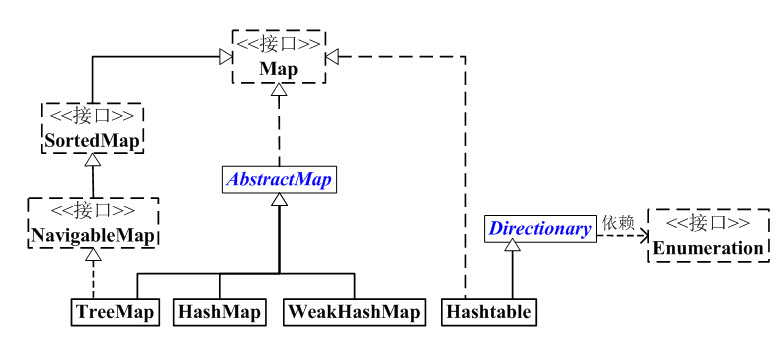
Map 是映射接口,Map中存储的内容是键值对(key-value)。
AbstractMap 是继承于Map的抽象类,它实现了Map中的大部分API。其它Map的实现类可以通过继承AbstractMap来减少重复编码。
SortedMap 是继承于Map的接口。SortedMap中的内容是排序的键值对,排序的方法是通过比较器(Comparator)。
NavigableMap 是继承于SortedMap的接口。相比于SortedMap,NavigableMap有一系列的导航方法;如”获取大于/等于某对象的键值对”、“获取小于/等于某对象的键值对”等等。
HashMap, Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类
- HashMap 是基于“拉链法”实现的散列表。一般用于单线程程序中。
- Hashtable 也是基于“拉链法”实现的散列表。它一般用于多线程程序中。
- WeakHashMap 也是基于“拉链法”实现的散列表,它一般也用于单线程程序中。相比HashMap,WeakHashMap中的键是“弱键”,当“弱键”被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强键。
- TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射。
Set
HashSet
HashSet 是一个没有重复元素的集合。
基于HashMap实现,仅存储键,通过对象的hashCode()方法和equals()方法来保证键值不重复,允许Null值。
1 | public class HashSet<E> |
TreeSet
TreeSet 是一个有序的集合。
基于TreeMap实现,仅存储键。其他属性和TreeMap类似
1 | public class TreeSet<E> extends AbstractSet<E> |
Set总结
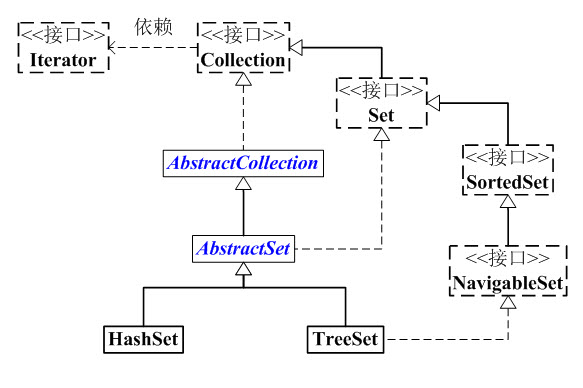
- Set 是继承于Collection的接口。它是一个不允许有重复元素的集合。
- AbstractSet 是一个抽象类,它继承于AbstractCollection,AbstractCollection实现了Set中的绝大部分函数,为Set的实现类提供了便利。
- HastSet 和 TreeSet 是Set的两个实现类。
- HashSet依赖于HashMap,它实际上是通过HashMap实现的。HashSet中的元素是无序的。
- TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。TreeSet中的元素是有序的。
Java Network
TCP/IP
Socket
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Socket socket = new Socket("192.168.1.1", 80);
//发送数据
OputputStream out = socket.getOutputStream();
out.write("some data".getBytes());
out.flush();
out.close();
//读取数据
InputStream in = socket.getInputStream();
int data = in.read();
...
in.close();
//关闭连接
socket.close();ServerSocket
1
2
3
4
5
6
7
8
9ServerSocket serverSocket = new ServerSocket(80);
boolean isStopped = false;
while(!isStopped) {
Socket clientSocket = serverSocket.accept(); //block
//关闭客户端Socket
clientSocket.close();
//关闭服务端Socket
serverSocket.close();
}
UDP
DatagramSocket
1
2
3
4
5
6
7
8
9
10
11
12//发送数据
byte[] buffer = new byte[65508]; //max length in a single UDP packet
InetAddress address = InetAddress.getByName("192.168.1.1");
DatagramPacket packet = new DatagramPacket(buffer, buffer.length, address, 80);
DatagramSocket datagramSocket = new DatagramSocket();
datagramSocket.send(packet);
//接收数据
DatagramSocket datagramSocket = new DatagramSocket(80);
byte[] buffer = new byte[1024];
DatagramPacket packet = new DatagramPacket(buffer,buffer.length);
datagramSocket.receive(packet); //block
byte[] receivedBuffer = packet.getData();
HttpURLConnection
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//Get请求
URL url = new URL("http://www.baidu.com");
HttpURLConnection urlConnection = (HttpURLConnection)url.openConnection();
urlConnection.setRequestMethod("GET");
InputStream input = urlConnection.getInputStream();
int data = input.read();
while(data != -1) {
System.out.print((char) data);
data = input.read();
}
//POST请求
urlConnection.setDoOutput(true);
urlConnection.setDoInput(true);
urlConnection.setRequestMethod("POST");
OutputStream output = urlConnection.getOutputStream();
byte[] postData = new byte[1024];
output.write(postData);
output.close();
input.close();InetAddress/InetSocketAddress
InetAddress
1
2
3//获取IP地址
InetAddress address = InetAddress.getByName("www.baidu.com");
InetAddress address = InetAddress.getLocalHost();InetSocketAddress
1
SocketAddress socketAddress = new InetSocketAddress(InentAddress.getLocalHost(), 80);